Parsing SYMCLI's XML Output with Python
Pretty much any SYMCLI command can be output in XML format by adding the optional flag “-output xml_e”. This flag can be used in both online and offline mode – see this post for more information on offline SYMCLI. The XML output provides an easy and more accurate way to programmatically parse SYMCLI command output (instead of screen scraping), or to import SYMCLI output into a spreadsheet. This post will provide an example of parsing SYMCLI XML with Python to produce a report showing capacity information per Storage Group, including cascaded (parent/child) storage groups.
For this exercise, I used Python 2.7.6 on CentOS 6.5 with the optional ‘prettytable’ library. The prettytable library is not part of the standard library, but can be easily installed with pip (‘pip install prettytable’).
The full script described in this post is located here.
First, we import the subprocess library so we can call SYMCLI commands and capture their output. Then we import the ElementTree library for parsing the SYMCLI output. If you have it on your system, I’d recommend using cElementTree for performance reasons. You can find a good tutorial on ElementTree at Eli Bendersky’s blog here. The last few commands below capture the XML output of the command “symcfg list -tdev -gb” into a string, and then create an ElementTree object (tdevtree) from that string.
import subprocess
import xml.etree.ElementTree as ET
sid = '0240'
tdevcommand = 'symcfg -sid ' + sid + ' list -tdev -gb -output xml_e'
tdev_xml = subprocess.check_output(tdevcommand, shell=True)
tdevtree = ET.fromstring(tdev_xml)
Before we move on, let’s examine an excerpt from the XML output of the SYMCLI command we’re currently parsing. The root element is
We want to capture information on TDEV capacity, so we’ll focus on the latter child element. Under
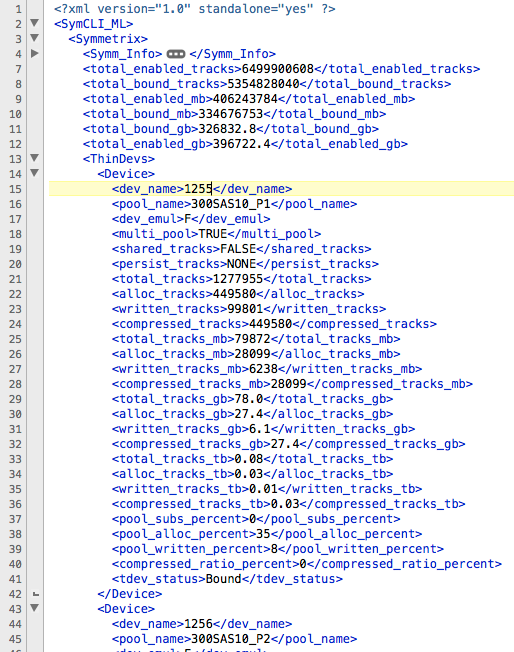
Moving back to the script, we’re going to iterate through all TDEVs (
First we initialize the dictionary (tdevcap), and then we use use ElementTree’s iterfind method with an XPath search string (‘Symmetrix/ThinDevs/Device’) to create an iterator for our ‘for’ loop. Each time through the for loop, we’ll be working against a single TDEV, and within the loop we’ll place information about each TDEV into our dictionary.
### Put TDEV ElementTree values into Python data structure
# tdevcap{ 'tdev1': [1024, 512, 512] } # [total, allocated, written]
tdevcap = dict()
# Iterate through all TDEVs, capturing capacity information
for elem in tdevtree.iterfind('Symmetrix/ThinDevs/Device'):
totalGb = float(elem.find('total_tracks_gb').text)
allocGb = float(elem.find('alloc_tracks_gb').text)
writnGb = float(elem.find('written_tracks_gb').text)
tdevcap[elem.find('dev_name').text] = [totalGb, allocGb, writnGb]
Now we need to capture information about the Storage Groups and their contents. This information isn’t available in the “symcfg list -thin -pool” command, so we’ll need to run another SYMCLI command, capture its XML output, and create another ElementTree object. In this case, we want to use the “symsg list -v” command. We’re going to take the output of this command and calculate the total capacity information of each storage group, along with its parent and child relationship information. We’ll put this information into a handful of dictionaries, so let’s initialize those dictionaries now as well. These dictionaries are similar to the last one – the keys are storage group names, and the values are lists. Descriptions of each dictionary’s contents are in the comments below.
### Capture SYMCLI SG information into ElementTree
sgcommand = 'symsg -sid ' + sid + ' list -v -output xml_e'
symsg_xml = subprocess.check_output(sgcommand, shell=True)
sgtree = ET.fromstring(symsg_xml)
### Put SG ElementTree values into Python data structure
# sgcapacity{ 'sg1': [1024, 512, 512] } # [total, allocated, written]
sgcapacity = dict()
# sgparents { 'sg1': [ 'parentsg1', 'parentsg2', 'parentsg3']}
sgparents = dict()
# sgchildren{ 'sg1': [ 'childsg1', 'childsg2', 'childsg3']}
sgchildren = dict()
Now we have another ElementTree object with Storage Group information. The symsg output is more complicated, on account of the possibility of cascaded storage groups. The root element is again
<SG_Info>, which contains the storage group’s name, along with a sub-section calledwith a list of Parent or Child storage groups relative to it <DEVS_List>, which contains a sub-section calledfor each member device (including members which are in Child storage groups)
The next section of the script makes up the bulk of the code. Here, we again use XPath and iterfind several times, throughout several nested for loops. In the main loop, we’re iterating through each Storage Group (each
# Iterate through all SGs
for elem in sgtree.iterfind('SG'):
# Initialize data structures to default values
sgname = elem.find('SG_Info/name').text # Current Storage Group name
sgcapacity[sgname] = [0,0,0]
sgchildren[sgname] = list()
sgparents[sgname] = list()
# Iterate through an SG's device members for members and their capacity
for member in elem.iterfind('DEVS_List/Device'):
membername = member.find('dev_name').text # Current SymDev (member) name
if membername in tdevcap:
# We've found a TDEV; record actual total/allocated/written capacity
devcapacity = tdevcap[membername]
else:
# We've found a Non-TDEV (e.g. STD); report all capacity values as total capacity
stdcap = float(member.find('megabytes').text)/1024
devcapacity = [stdcap, stdcap, stdcap]
# Add this device's capacity info to the running tally for this SG
sgcapacity[sgname] = map(sum, zip(sgcapacity[sgname],devcapacity))
# Iterate through an SG's SG members for Parent/Child information
for cascadesg in elem.iterfind('SG_Info/SG_group_info/SG'):
if cascadesg.find('Cascade_Status').text == 'IsChild':
# We've found a Child SG; add it to the sgchildren[sgname] dictionary
childname = cascadesg.find('name').text
if childname not in sgchildren[sgname]:
sgchildren[sgname].append(childname)
elif cascadesg.find('Cascade_Status').text == 'IsParent':
# We've found a Parent SG; add it to the sgparents[sgname] dictionary
parentname = cascadesg.find('name').text
if parentname not in sgparents[sgname]:
sgparents[sgname].append(parentname)
Finally, we build a PrettyTable object from these dictionaries, format the table, and print it. This section could easily be replaced or augmented to output in alternate formats, such as CSV.
# Note prettytable is not part of the standard Python Library; install it with pip
from prettytable import PrettyTable
report = PrettyTable(['Storage Group', 'Total GB', 'Allocated GB', 'Written GB', 'Parents', 'Children'])
for sg, mb in sgcapacity.items():
children, parents = ['', '']
if sg in sgchildren:
children = ','.join(sgchildren[sg])
if sg in sgparents:
parents = ','.join(sgparents[sg])
report.add_row([sg, sgcapacity[sg][0], sgcapacity[sg][1], sgcapacity[sg][2], parents, children])
report.int_format = '10'
report.float_format = '10.1'
report.max_width['Children'] = 30
report.format = True
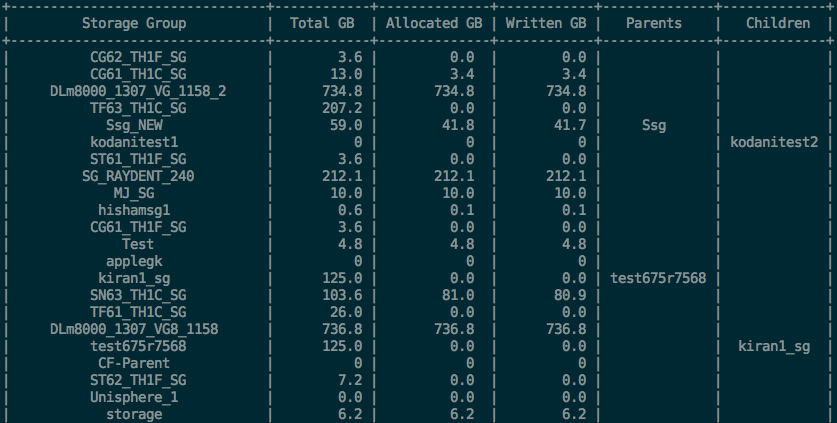
print(report)
And that’s it. Our output should look something like this: